[Database] JOIN 문제풀이
[Database] JOIN [Database] 기초 문제풀이 [Database] - Group 함수 (그룹함수) [Database] 함수 - 집합연산자와 분석함수 [Database] 여러 함수 [Database] 함수 : 숫자, 날짜 함수 그리고 변환 함수 [Database] 함수 : 문
hong-study.tistory.com
서브 쿼리
서브쿼리는 다른 SELECT 문장의 절에 내장된 SELECT 문장이다.
▶ 서브쿼리를 사용하여 간단한 문장을 강력한 문장으로 만들 수 있다.
▶ 테이블 자체의 데이터에 의존하는 조건으로 테이블의 행을 검색할 필요가 있을 때 서브쿼리는 아주 유용하다.


서브쿼리를 사용할 때 주의 사항
● 서브쿼리는 괄호로 둘러싸야 한다.
● 서브쿼리는 비교 연산자의 오른쪽에 있어야한다.
● 서브 쿼리는 ORDER BY 절을 포함할 수 없다.
▶ SELECT 문장은 오직 하나의 ORDER BY를 가질 수 있으면, 전체 문장의 마지막에 있어야한다.
● 서브쿼리에서는 두 종류의 비교 연산자를 사용한다.
단일행 서브쿼리에는 단일 행 연산자를 사용해야 하며, 다중행 서브쿼리에서는 다중 행 연산자를 사용해야한다.
단일행 서브쿼리
단일 행 서브쿼리는 내부 SELECT 문장으로부터 하나의 행을 리턴하는 질의이다.
▶ 이런 유형의 서브쿼리는 단일 행 연산자를 사용한다.

단일행 연산자를 사용하는 서브쿼리는 반드시 한 개 행 또는 0개 행을 반환해야 한다.
WHERE 절에서 서브쿼리가 두 개 행 이상 한다면 다음 절에서 설명하는 다중 행 서브쿼리 연산자를
이용해야 한다.
서브쿼리 작성 방법
아래 구문을 함께 확인하면서 작성 방법에 대해 생각한다.
▶ EMPLOYEES 테이블에서 Nancy의 급여보다 높은 급여의 사람들을 찾는 구문을 작성하려고 할 때
처음에 Nancy의 급여 정도에 대해서 찾는 구문을 작성한다.
SELECTSALARY FROM EMPLOYEES WHERE FIRST_NAME = 'Nancy';
→ 이렇게 작성할 경우, 여러 조건들과 함께 구문이 복잡해져, 단일 행 서브쿼리를 이용하여 간단하게 해결한다.
SELECT * FROM EMPLOYEES WHERE SALARY >= (SELECT SALARY FROM EMPLOYEES WHERE FIRST_NAME = 'Nancy');
다중 행 서브쿼리
서브쿼리 결과가 2개 행 이상일 경우 다중 행 서브쿼리라고 한다.
▶ 다중 행 서브쿼리일 경우 사용되는 연산자가 다르다.

앞서 단일 행 연산자에서 'Nancy'를 찾을 때는 FIRST_NAME 의 데이터 중 'Nancy' 를 가진 데이터가 한 행만
존재했기 때문에 단일행 연산자가 에러 없이 정상 동작하였다.
▶ 하지만, 위처럼 'David'의 경우 3행이 EMPLOYEES 테이블에 존재하기 때문에 단일행 연산자를 실행시
에러가 발생하게 된다.
다중행 서브쿼리 연산자
● IN : 목록의 어떤 값과 같은지 확인
● ANY, SOME : 값을 서브쿼리에 의해 리턴된 각각의 값을 비교한다. 하나라도 만족하면 된다.
● ALL : 값을 서브쿼리에 의해 리턴된 모든 값과 비교한다. 모든 값과 비교해서 만족해야 한다.
● EXISTS : 결과를 만족하는 값이 존재하는지 여부를 확인한다.
ALL과 ANY의 차이점
● < ANY : 가장 큰 값보다 작으면 된다.
● > ANY : 가장 작은 값보다 크면 된다.
● < ALL : 가장 작은 값보다 작아야 한다.
● > ALL : 가장 큰 값보다 커야 한다.
● = ANY : IN과 같은 역할을 한다.
SELECT SALARY FROM EMPLOYEES WHERE FIRST_NAME = 'David';
David 라는 이름을 가진 행을 검색하면 아래와 같이 총 3개의 행이 나온다.

- > ANY, SOME 를 사용할 경우
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE
SALARY > ANY (SELECT SALARY FROM EMPLOYEES WHERE FIRST_NAME = 'David');
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE
SALARY > SOME (SELECT SALARY FROM EMPLOYEES WHERE FIRST_NAME = 'David');David SALARY의 값이 4800이 가장 최솟값이기 때문에, 4800보다 큰 수가 모두 출력된다.

- < ANY, SOME 를 사용할 경우
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE
SALARY < ANY (SELECT SALARY FROM EMPLOYEES WHERE FIRST_NAME = 'David');
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE
SALARY < SOME (SELECT SALARY FROM EMPLOYEES WHERE FIRST_NAME = 'David');David 의 SALARY 데이터 최댓값이 9500 이므로, 9500보다 작은 모든 데이터가 검색된다.

- > ALL 을 사용할 경우
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE
SALARY > ALL (SELECT SALARY FROM EMPLOYEES WHERE FIRST_NAME = 'David');SALARY의 최댓값인 9500보다가 많은 급여를 받는 사람의 정보를 모두 검색한다.

- < ALL 을 사용할 경우
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY < ALL (SELECT SALARY FROM EMPLOYEES WHERE FIRST_NAME = 'David');최솟값인 4800보다 작은 급여를 받는 사람들에 대한 정보가 모두 검색된다.

- IN 을 사용할 경우
IN 의 경우 찾고자 하는 다중행의 결과값과 동일한 행들을 검색한다.
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE
SALARY IN (SELECT SALARY FROM EMPLOYEES WHERE FIRST_NAME = 'David');
스칼라(Scalar) 서브 쿼리
SELECT 절에 사용하는 서브쿼리이다.
스칼라 서브쿼리를 이용하면 다양한 결과를 도출할 수 있으며, 특히 조인을 수행할 시 조인할 행의 수를 줄여
성능을 향상시킬 수 있다.
한 행에서 정확히 하나의 열 값만 반환하는 서브쿼리로, 동일한 입력값이 들어오면 수행 횟 수를 최소화한다.
스칼라 서브쿼리의 장점
Query Execution Cache 기능이 수행된다.
▶ 키 값이 없는 데이터가 입력시 NULL 값으로 리턴하는데, 결과는 Outer Join과 같이 나타난다.
기존 JOIN 문을 사용할 경우
SELECT FIRST_NAME, DEPARTMENT_NAME
FROM EMPLOYEES E
JOIN DEPARTMENTS D
ON ( E.DEPARTMENT_ID = D.DEPARTMENT_ID )
ORDER BY FIRST_NAME;

SCALAR 문을 사용할 경우
SELECT FIRST_NAME,
(SELECT DEPARTMENT_NAME FROM DEPARTMENTS D
WHERE D.DEPARTMENT_ID = E.DEPARTMENT_ID) DN
FROM EMPLOYEES E
ORDER BY FIRST_NAME;
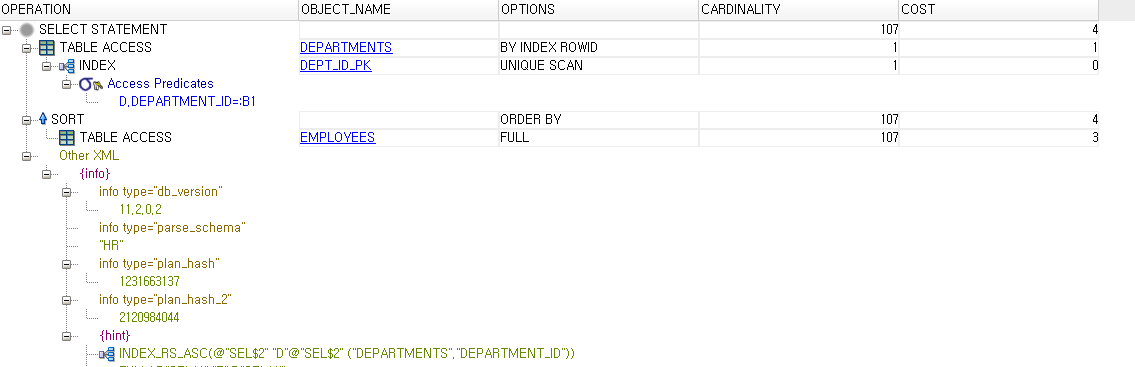
CARDINALITY 와 COST
● CARDINALITY
어떤 쿼리를 날려서 수행 결과 나오는 로우수를 말한다. ( 선택도 )
전체 ROW 수 * 선택도 = 결과수 ▶ 즉, CARDINALITY 가 된다.
이는 곧 CARDINALITY가 높을 수록 행의 수와 작업량이 많다는 것을 의미한다.
● COST
비용은 사용된 자원이나 작업의 단위를 나타낸다.
CBO는 작업의 단위로써 disk I/O, CPU 사용, Memory 사용을 사용한다.
JOIN문과 SCALAR 비교
JOIN문과 SCALAR문의 결과값은 동일하지만, CARDINALITY와 COST를 비교해보면,
JOIN문의 작업량이 SCALAR문보다 월등히 높은 것을 볼 수 있다.
※ 그렇다고 SCALAR 문이 훨씬 효율적이라는 것보다 때에 따라
적재적소에 맞게 JOIN 이든 SCALAR를 사용해야 한다는 것이다.
▶ 데이터가 많은 경우 : JOIN이 유리
▶ 컬럼(인덱스) 참조가 가능한 경우 : SCALAR 가 유리
▶ 컬럼(인덱스) 참조가 불가능한 경우 : JOIN이 유리
인라인뷰 ( Inline View )
SELECT 절의 결과를 FROM 절에서 하나의 테이블처럼 사용하고 싶을 때 사용한다.
FROM절에 서브쿼리가 온다.
FROM절에는 테이블 또는 뷰가 올 수 있다.
※ VIEW 도 하나의 SELECT문이므로 FROM 절에 사용하는 서브쿼리도 하나의 뷰로 볼 수 있다.
▶ FROM 절에 오는 뷰를 INLINE VIEW 라고 한다.
SELECT ROWNUM, FIRST_NAME, SALARY
FROM (SELECT FIRST_NAME, SALARY
FROM EMPLOYEES ORDER BY SALARY DESC)
WHERE ROWNUM BETWEEN 1 AND 10;
SELECT * FROM(
SELECT FIRST_NAME || ' '|| LAST_NAME AS NAME,
TO_CHAR(SALARY + SALARY * NVL(COMMISSION_PCT, 0), 'L999,999,999') AS SALARY,
NVL(COMMISSION_PCT,0) AS COMMISSION_PCT,
TO_CHAR(HIRE_DATE, 'YYYY"년"MM"월"DD"일"') AS HIRE_DATE,
TRUNC( (SYSDATE - HIRE_DATE) / 365 ) AS 근속년수
FROM EMPLOYEES
ORDER BY FIRST_NAME
) WHERE MOD( 근속년수, 5) = 0;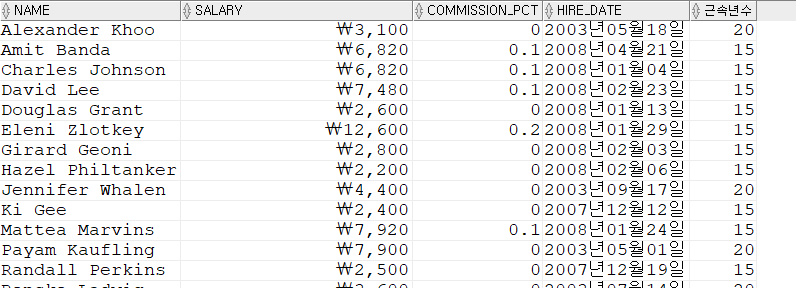
'Programming > Database' 카테고리의 다른 글
| [Database] DML ( Data Manipulation Language ) (0) | 2023.12.11 |
|---|---|
| [Database] 서브쿼리 문제풀이 (0) | 2023.12.07 |
| [Database] JOIN 문제풀이 (0) | 2023.12.06 |
| [Database] JOIN (0) | 2023.12.06 |
| [Database] 기초 문제풀이 (0) | 2023.12.05 |



